January 23, 2024
UNC Computer Science researchers made a splash at the 2023 Conference and Workshop on Neural Information Processing Systems (NeurIPS). Current and future UNC CS personnel had 14 papers accepted.
NeurIPS is an academic conference on machine learning and computational neuroscience, with research also presented from related fields like computer vision and statistical linguistics. The research presented by current and future UNC personnel focused on a wide range of topics, including object recognition, video question answering, multimodal generation, explainable AI, meta-learning, and more.
Nine of the publications accepted by the conference for 2023 came from the MURGe-Lab, which is led by Professor Mohit Bansal. Assistant Professor Huaxiu Yao also had two papers accepted, as did Tianlong Chen, who will join UNC CS as an assistant professor beginning in the 2024-2025 academic year. Assistant Professor and computer vision researcher Roni Sengupta also had a paper accepted.
Of those 14 accepted papers, two were selected for “spotlight” (top 5%) by the conference. The first spotlight paper is a collaboration between UNC CS and Google titled, “Does Localization Inform Editing? Surprising Differences in Causality-Based Localization vs. Knowledge Editing in Language Models.” The paper finds that we can change how a fact is stored in a model by editing weights that are in a different location than where existing methods suggest that the fact is stored. The paper’s first author is Peter Hase, a doctoral student in computer science.
The second spotlight paper is titled, “Paxion: Patching Action Knowledge in Video-Language Foundation Models.” A collaboration between UNC CS and the University of Illinois at Urbana-Champaign, the project seeks to improve the temporal understanding of video-language models, which have traditionally relied more on object recognition than temporal understanding to accomplish certain tasks.
Below is a roundup of all UNC CS papers from the conference, organized by faculty adviser.
Mohit Bansal
Adaptive Contextual Perception: How To Generalize To New Backgrounds and Ambiguous Objects
Zhuofan Ying, Peter Hase, Mohit Bansal
This paper investigates how vision models adaptively use context for out-of-distribution (OOD) generalization and leverage our analysis results to improve model OOD generalization. First, Bansal’s group formulates two distinct OOD settings where the contexts are either irrelevant or beneficial, reflecting the diverse contextual challenges faced in biological vision. They then analyze model performance in these two different OOD settings and demonstrate that models that excel in one setting tend to struggle in the other. Next, to better understand the model properties contributing to OOD generalization, they use representational geometry analysis and probing methods to examine a population of models, and we discover that those with more factorized representations and appropriate feature weighting are more successful in handling Background-Invariance and Object-Disambiguation tests. They further validate these findings through causal intervention on representation factorization and feature weighting to demonstrate their causal effect on performance. Lastly, they propose new augmentation methods to enhance model generalization.
Any-to-Any Generation via Composable Diffusion
Zineng Tang, Ziyi Yang, Chenguang Zhu, Michael Zeng, Mohit Bansal
In this paper, Bansal’s group presents Composable Diffusion (CoDi), a novel generative model capable of generating any combination of output modalities, such as language, image, video, or audio, from any combination of input modalities. Unlike existing generative AI systems, CoDi can generate multiple modalities in parallel and its input is not limited to a subset of modalities like text or image. CoDi employs a novel composable generation strategy which involves building a shared multimodal space by bridging alignment in the diffusion process. Highly customizable and flexible, CoDi achieves strong joint-modality generation quality, and outperforms or is on par with the unimodal state-of-the-art for single-modality synthesis.
Can Language Models Teach? Teacher Explanations Improve Student Performance via Personalization
Swarnadeep Saha, Peter Hase, Mohit Bansal
A hallmark property of explainable AI models is the ability to teach other agents, communicating knowledge of how to perform a task. While Large Language Models perform complex reasoning by generating explanations for their predictions, it is unclear whether they also make good teachers for weaker agents. To address this, this paper considers a student-teacher framework between two LLM agents and studies if, when, and how the teacher should intervene with natural language explanations to improve the student’s performance.

Does Localization Inform Editing? Surprising Differences in Causality-Based Localization vs. Knowledge Editing in Language Models
Peter Hase, Mohit Bansal, Been Kim, Asma Ghandeharioun
In this paper, the authors show that we can change how a fact is stored in a model by editing weights that are in a different location than where existing methods suggest that the fact is stored. This is surprising because we would expect that localizing facts to specific model parameters would tell us where to manipulate knowledge in models, and this assumption has motivated past work on model editing methods.
PanoGen: Text-Conditioned Panoramic Environment Generation for Vision-and-Language Navigation
Jialu Li, Mohit Bansal
Vision-and-Language Navigation (VLN) requires the agent to follow language instructions to navigate through 3D environments. One main challenge in VLN is the limited availability of photorealistic training environments, which makes it hard to generalize to new and unseen environments. To address this problem, Bansal’s group proposes PanoGen, a generation method that can potentially create an infinite number of diverse panoramic environments conditioned on text. Empirically, learning with their PanoGen environments achieves the new state-of-the-art on the Room-to-Room, Room-for-Room, and CVDN datasets.
Paxion: Patching Action Knowledge in Video-Language Foundation Models
Zhenhailong Wang, Ansel Blume, Sha Li, Genglin Liu, Jaemin Cho, Zineng Tang, Mohit Bansal, Heng Ji
This paper introduced the Action Dynamics Benchmark (ActionBench) to test the multimodal alignment capabilities and temporal understanding of video-language models (VidLMs), which revealed that while VidLMs generally perform well on many recognition tasks, they rely heavily on recognizing objects in a video rather than understanding how actions happen in time. To remedy this, the authors presented Paxion, a framework to encode new action knowledge into VidLMs without compromising their existing capabilities.
Self-Chained Image-Language Model for Video Localization and Question Answering
Shoubin Yu, Jaemin Cho, Prateek Yadav, Mohit Bansal
While recent image-language models can efficiently bootstrap the representation learning of video-language models, they typically concatenate uniformly sampled video frames as visual inputs without explicit language-aware, temporal modeling. To address this issue, this paper proposes a novel framework that leverages a single image-language model to tackle both temporal keyframe localization and QA on videos.
Visual Programming for Step-by-Step Text-to-Image Generation and Evaluation
Jaemin Cho, Abhay Zala, Mohit Bansal
This paper proposes two novel interpretable/explainable visual programming frameworks for text-to-image (T2I) generation and evaluation. First, they introduce VPGen, an interpretable step-by-step T2I generation framework that decomposes T2I generation into three steps: object/count generation, layout generation, and image generation. Second, they introduce VPEval, an interpretable and explainable evaluation framework for T2I generation based on visual programming. Unlike previous T2I evaluations with a single scoring model that is accurate in some skills but unreliable in others, VPEval produces evaluation programs that invoke a set of visual modules that are experts in different skills, and also provides visual+textual explanations of the evaluation results.
TIES-Merging: Resolving Interference When Merging Models
Prateek Yadav, Derek Tam, Leshem Choshen, Colin Raffel, Mohit Bansal
Recently, model merging techniques have emerged as a solution to combine multiple task-specific models into a single multitask model without performing additional training. However, existing merging methods often ignore the interference between parameters of different models, resulting in large performance drops when merging multiple models. In this paper, authors demonstrate that prior merging techniques inadvertently lose valuable information due to two major sources of interference: (a) interference due to redundant parameter values and (b) disagreement on the sign of a given parameter’s values across models. To address this, they propose the method, TRIM, ELECT SIGN & MERGE (TIES-Merging), which introduces three novel steps when merging models: (1) resetting parameters that only changed a small amount during fine-tuning, (2) resolving sign conflicts, and (3) merging only the parameters that are in alignment with the final agreed-upon sign.
Roni Sengupta
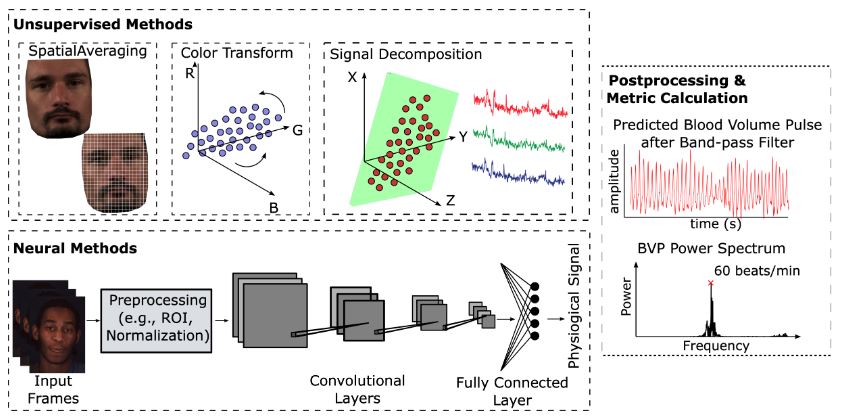
rPPG-Toolbox: Deep Remote PPG Toolbox
Xin Liu, Girish Narayanswamy, Akshay Paruchuri, Xiaoyu Zhang, Jiankai Tang, Yuzhe Zhang, Roni Sengupta, Shwetak Patel, Yuntao Wang, Daniel McDuff
Camera-based physiological measurement is a fast growing field of computer vision. Remote photoplethysmography (rPPG) utilizes imaging devices (e.g., cameras) to measure the peripheral blood volume pulse (BVP) via photoplethysmography, and enables cardiac measurement via webcams and smartphones. However, the task is non-trivial with important pre-processing, modeling, and post-processing steps required to obtain state-of-the-art results. Replication of results and benchmarking of new models is critical for scientific progress; however, as with many other applications of deep learning, reliable codebases are not easy to find or use. We present a comprehensive toolbox, rPPG-Toolbox, that contains unsupervised and supervised rPPG models with support for public benchmark datasets, data augmentation, and systematic evaluation: https://github.com/ubicomplab/rPPG-Toolbox
Huaxiu Yao
An Iterative Self-Learning Framework for Medical Domain Generalization
Zhenbang Wu, Huaxiu Yao, David Liebovitz, Jimeng Sun
Deep learning models have been widely used to assist doctors with clinical decision-making. However, these models often encounter a significant performance drop when applied to data that differs from the distribution they were trained on. This challenge is known as the domain shift problem. Existing domain generalization algorithms attempt to address this problem by assuming the availability of domain IDs and training a single model to handle all domains. However, in healthcare settings, patients can be classified into numerous latent domains, where the actual domain categorizations are unknown. Furthermore, each patient domain exhibits distinct clinical characteristics, making it sub-optimal to train a single model for all domains. To overcome these limitations, we propose SLGD, a self-learning framework that iteratively discovers decoupled domains and trains personalized classifiers for each decoupled domain. We evaluate the generalizability of SLGD across spatial and temporal data distribution shifts on two real-world public EHR datasets: eICU and MIMIC-IV. Our results show that SLGD achieves up to 11% improvement in the AUPRC score over the best baseline.
Meta-Learning with Neural Bandit Scheduler
Yunzhe Qi, Yikun Ban, Tianxin Wei, Jiaru Zou, Huaxiu Yao, Jingrui He
Meta-learning has been proven an effective learning paradigm for training machine learning models with good generalization ability. Apart from the common practice of uniformly sampling the meta-training tasks, existing methods working on task scheduling strategies are mainly based on pre-defined sampling protocols or the assumed task-model correlations, and greedily make scheduling decisions, which can lead to sub-optimal performance bottlenecks of the meta-model. In this paper, we propose a novel task scheduling framework under Contextual Bandits settings, named BASS, which directly optimizes the task scheduling strategy based on the status of the meta-model. By balancing the exploitation and exploration in meta-learning task scheduling, BASS can help tackle the challenge of limited knowledge about the task distribution during the early stage of meta-training, while simultaneously exploring potential benefits for forthcoming meta-training iterations through an adaptive exploration strategy. Theoretical analysis and extensive experiments are presented to show the effectiveness of our proposed framework.
Tianlong Chen (joining UNC CS for 2024-2025)
H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, Zhangyang Wang, Beidi Chen
Large Language Models (LLMs), despite their recent impressive accomplishments, are notably cost-prohibitive to deploy, particularly for applications involving long-content generation, such as dialogue systems and story writing. Often, a large amount of transient state information, referred to as the KV cache, is stored in GPU memory in addition to model parameters, scaling linearly with the sequence length and batch size. In this paper, we introduce a novel approach for implementing the KV cache which significantly reduces its memory footprint. Our approach is based on the noteworthy observation that a small portion of tokens contributes most of the value when computing attention scores. We call these tokens Heavy Hitters (H2). Through a comprehensive investigation, we find that (i) the emergence of H2 is natural and strongly correlates with the frequent co-occurrence of tokens in the text, and (ii) removing them results in significant performance degradation. Based on these insights, we propose Heavy Hitter Oracle (H2O), a KV cache eviction policy that dynamically retains a balance of recent and H2 tokens. We formulate the KV cache eviction as a dynamic submodular problem and prove (under mild assumptions) a theoretical guarantee for our novel eviction algorithm which could help guide future work. We validate the accuracy of our algorithm with OPT, LLaMA, and GPT-NeoX across a wide range of tasks. Our implementation of H2O with 20% heavy hitters improves the throughput over three leading inference systems DeepSpeed Zero-Inference, Hugging Face Accelerate, and FlexGen by up to 29×, 29×, and 3× on OPT-6.7B and OPT-30B. With the same batch size, H2O can reduce the latency by up to 1.9×. The code is available at https://github.com/FMInference/H2O.
The Emergence of Essential Sparsity in Large Pre-trained Models: The Weights that Matter
Ajay Jaiswal, Shiwei Liu, Tianlong Chen, Zhangyang Wang
Large pre-trained transformers are show-stealer in modern-day deep learning, and it becomes crucial to comprehend the parsimonious patterns that exist within them as they grow in scale. With exploding parameter counts, Lottery Ticket Hypothesis (LTH) and its variants, have lost their pragmatism in sparsifying them due to high computation and memory bottleneck of repetitive train-prune-retrain routine of iterative magnitude pruning (IMP) which worsens with increasing model size. This paper comprehensively studies induced sparse patterns across multiple large pre-trained vision and language transformers. We propose the existence of — essential sparsity defined with a sharp dropping point beyond which the performance declines much faster w.r.t the rise of sparsity level, when we directly remove weights with the smallest magnitudes in one-shot without re-training. We also find essential sparsity to hold valid for N:M sparsity patterns as well as on modern-scale large language models (Vicuna-7B). We also present an intriguing emerging phenomenon of abrupt sparsification during the pre-training of BERT, i.e., BERT suddenly becomes heavily sparse in pre-training after certain iterations. Moreover, our observations also indicate a counter-intuitive finding that BERT trained with a larger amount of pre-training data tends to have a better ability to condense knowledge in comparatively relatively fewer parameters. Lastly, we investigate the effect of the pre-training loss on essential sparsity and discover that self-supervised learning (SSL) objectives trigger stronger emergent sparsification properties than supervised learning (SL). The code is available at https://github.com/VITA-Group/essential_sparsity.