
December 18, 2023
Above: Using a video of a still subject (left) and a driving video of a subject speaking (center), one paper presented at WACV 2024 highlights the ability to output a motion-augmented third video (left) with the original PPG signals intact.
The 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) will feature impactful computer vision research from UNC Computer Science. UNC CS researchers had two publications accepted at the conference, one of which was selected for an oral presentation, a distinction reserved for the top 2.6 percent of papers at the conference.
Enhancing physiological measurement through motion augmentation
The paper selected for oral presentation is titled, “Motion Matters: Neural Motion Transfer for Better Camera Physiological Measurement.” Authored by Akshay Paruchuri, Xin Liu, Yulu Pan, Shwetak Patel, Daniel McDuff, and Roni Sengupta (with the latter two providing equal advising), the project is a collaboration between UNC and the University of Washington. Paruchuri and Pan are computer science graduate students at UNC, and Sengupta is an assistant professor.
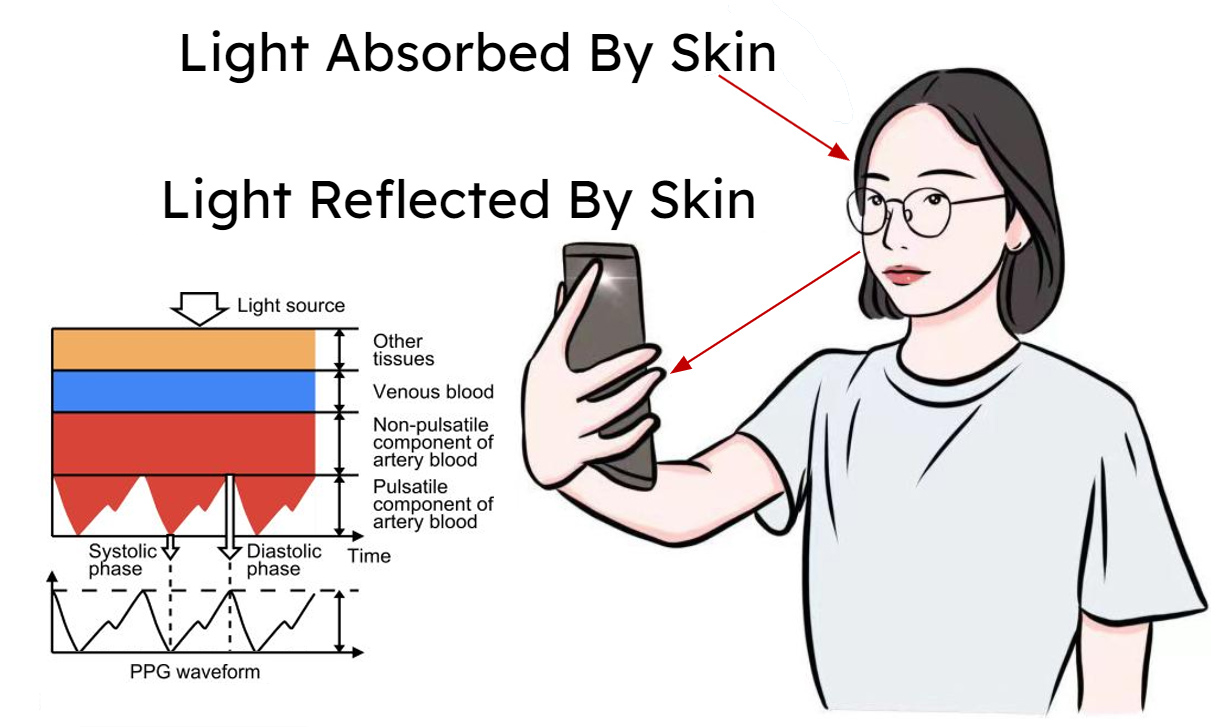
The paper deals with physiological measurement via cameras. By measuring light reflected from the body, we can measure changes in the blood volume pulse beneath the skin. Supervised neural models can extract physiological metrics like cardiac waveforms including photoplethysmography (PPG) signals. This technology, known as remote PPG (rPPG), turns webcams and smartphones into health sensors that can monitor respiration, heart rate variability, arrhythmias, and blood pressure, potentially expanding healthcare access worldwide.
As with most neural models, the usefulness of the model is inherently limited by the quality of the training data. Accuracy is critical in health sensing, and a lack of representative training data showing natural body movements can make it difficult to accurately measure the vital signs of someone in an unconstrained setting. Even having the subject of a video move their head or talk normally can lower the accuracy of the measurements.
The solution to this limitation is an expansion of training data, supplementing existing datasets with training videos involving subjects in motion. There are a few ways this could be done. Creating a new dataset of videos featuring more motion would be ideal, but extremely time-consuming. Alternatively, a new dataset could be generated using computer animation, but that is a resource-intensive process that may still result in unnatural movements and lighting with minimal benefit to the model’s ability to generalize to real-world videos.
Instead, the team explored neural motion transfer techniques to add more motion diversity to existing synthetic and real-world training data. Beginning with a training video of a stationary subject, a second “driving” video with a desired amount of motion is selected from a large dataset of videos of people speaking. The motion in the driving videos can be both rigid (such as head rotation) and non-rigid (such as talking) to maximize motion diversity. The natural body movements from the driving video are applied to the subject of the original training video in order to generate a new video, in which the formerly stationary subject mimics the motions of the person in the driving video. The resulting video maintains the fidelity of the underlying PPG signal from the original source video.
The video above shows three existing training videos (top row), three driving videos (middle row), and the results of augmenting the training videos with the motion from the driving videos.
With motion augmented training data, the team saw a significant improvement of up to 47 percent over other, state-of-the-art methods and up to 79 percent across five benchmark datasets. Neural methods for the task of rPPG will now be much more accurate when dealing with videos that have more motion than existing datasets used for training.
The paper is available online, and more information can be found on the project website.
A joint approach to depth prediction and segmentation
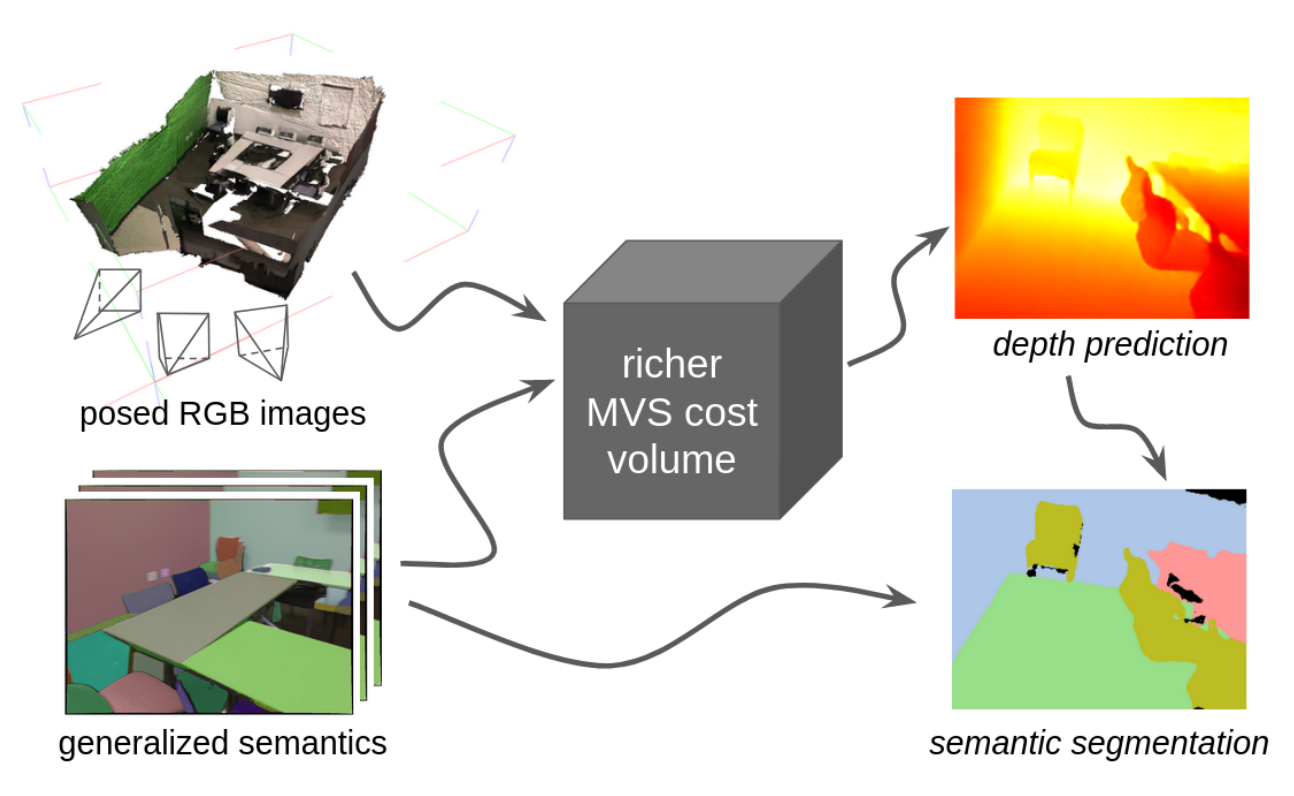
The second UNC CS paper accepted by the conference is titled, “Joint Depth Prediction and Semantic Segmentation with Multi-View SAM.” It was authored by computer science graduate students Mykhailo Shvets, Dongxu Zhao, Professor Marc Niethammer, Assistant Professor Roni Sengupta, and University of California, Irvine Professor Alexander C. Berg, who was formerly an associate professor at UNC.
The paper deals with depth prediction and semantic segmentation, which are core tasks for helping a robot perceive and navigate its environment. Semantic segmentation is the recognition of what objects in the environment are, and depth prediction is the understanding of where the objects are within the scene.
Depth information can aid in segmentation, and vice versa, so processing both tasks jointly with a multi-task approach can be beneficial. This is especially true when the environment is only viewed in 2D from one viewpoint, the scene needs to be analyzed from only a few frames of video, or when the scene is dynamic or only partially visible.
This paper introduces a joint depth and segmentation prediction network using the multi-view stereo (MVS) framework which can reason about a 3D scene using only a few images. The previous joint depth and segmentation approaches are either 2D or require a full dense scan of the environment. The MVS technique for depth prediction benefits from semantic segmentation features of the popular Segment Anything Model (SAM). The new joint approach consistently outperforms single-task MVS and segmentation models, along with multi-task 2D methods.
The paper is available online.