COMP 790.139: Natural Language Processing (Fall 2017): Coding Homework 1 (Word Embedding Training, Visualization, Evaluation)¶
Created by TA Yixin Nie (Instructor: Mohit Bansal)
Instructions¶
All the instructions are present in the jupyter notebook (as shown in the class; and see an html preview below).
Install jupyter notebook in your python environment and download the file below.
https://drive.google.com/drive/folders/0B6i0pVGwapCdaU9KYmFZNEFGZmM?usp=sharing
Use this directory as your workspace and write your code in the “hw1.ipynb” file. You could also add extra images or tables in the directory and link them into “hw1.ipynb” file but grading will only base on the “hw1.ipynb” file.
Make sure to name your directory as "<your_name>_hw1" and compress it to "<your_name>_hw1.zip".
Email the file to comp790.hw@gmail.com for submission.
Homework 1 Preview¶
The main goals for homework 1 are:
- Setting up your python environment.
- Getting familiar with the most popular deep learning framework (Pytorch, Tensorflow).
- Starting your very first NLP project by training a toy word embedding from scratch.
- Visualizing your word vectors.
- Trying to learn to interpret your results.
Notice:
You can test or run your code in any environment but you could only show your codes, your results and your write-ups in this single notebook file. We will not re-run your code for grading.
1. Setup python environment (1 pt)¶
We will use python3.x throughout this course and make sure to have the packages (listed below) installed in your python environment.
Required packages:
numpy
ipython
jupyterRecommended packages:
torch
torchvision
tensorflow
tqdm
scikit-learn
matplotlib
nltk
spacyYou can use pytorch or tensorflow for building your neural network model. However, I highly recommend using pytorch as your default deep learning toolkit.
2. Loading data (0.5 pt)¶
Successful opening this file means that you have set up your jupyter notebook and ready to code. Now that the first thing you need to do is to load the dataset. The dataset is in the file "dataset.txt" and it contains almost 19k sentences. Loading all the sentences into an array (one sentence per item) and print out the total length. Write and run your code in the next cell.
3. Preprocessing¶
(1). Tokenization (0.5 pt)¶
For many NLP tasks, the first thing you need to do is to tokenize your raw text into lists of words. You can use spacy or nltk to tokenize the sentences or you can just use split(" ") to break the sentences into a list of words.
Write and run your code in the next cell to tokenize all the sentences.
(2). Showing word statistics (0.5 pt)¶
Using Counter in python to calculate the frequency for each word in the dataset.
Show the frequency for words in ['man', 'woman', 'is', 'was'].
(3). building vocabulary (0.5)¶
Select the top K most frequent word in the dataset and build a vocabulary for those words. (You can set K=1000 for now.)
Building a vocabulary is nothing more than assigning a unique id to each word in the dataset. So, a vocabulary is basically a dictionary and an array in python data structure. The dictionary will convert the word to a number and the array will convert a given number to a word.
# e.g.
stoi['love'] = 520
itos[520] = 'love'
# stoi = dict()
# itos = []
(3) Rearranging (5 pt)¶
Read http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/ and then rearrange your data.
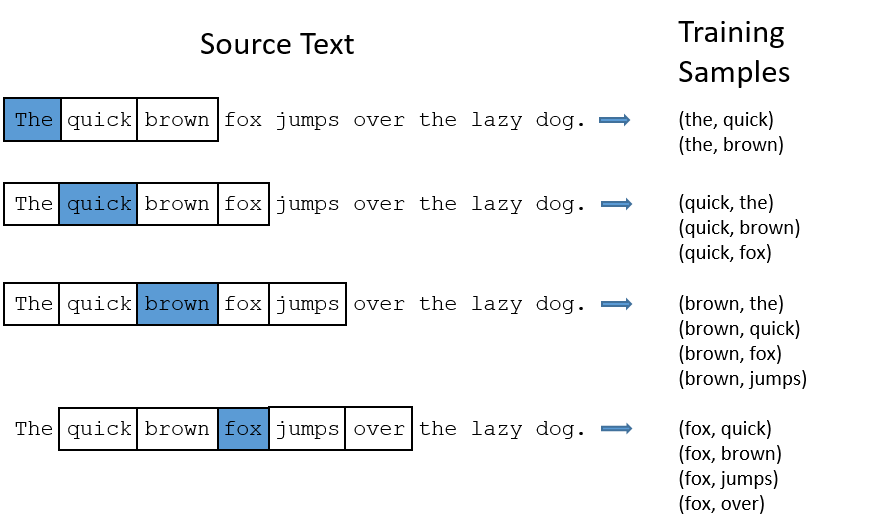
The final structure of your data should be a long list of tuples (x, y).
x is the id of the target word (the center word in current window) and y is the id of the context word.
Write your code in the cell below. Print out the total length of all your samples.
Notice:
For now, you can just ignore the words that are not in the set of the top K most frequent words.
4. Build word embedding (skip-gram) model. (15 pt)¶
It's time to build your very first NLP neural network model, the skip-gram model!
You should first read tutorials for pytorch http://pytorch.org/tutorials/ or tensorflow if you are not familiar with the neural network frameworks and models.
Some key concepts you need to know:
- Softmax and cross entropy loss.
- Batching. (esp. why do we need batch and how?)
- Forward and backward propagation.
Keep it in mind that the model will have two trainable matrices, namely the word embedding matrix and the context embedding matrix.
Write your code in the cell below and print out the shape of all the parameters in your model.
(It should be something like [vocabulary_size * word_embedding_dimension].)
Read http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model carefully again before building your neural network.
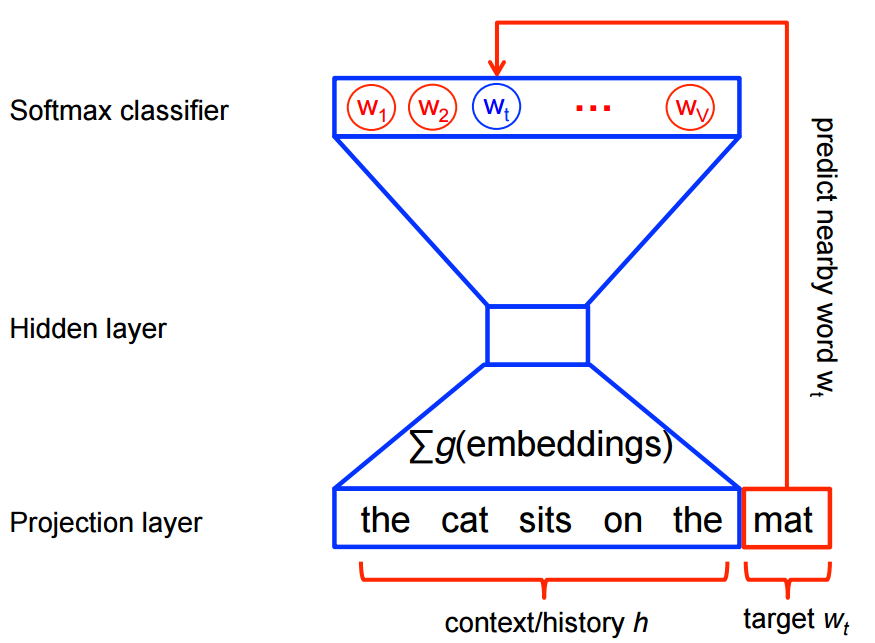
5. Train the neural model.¶
(1). Converting data type and batching. (5 pt)¶
Before training your neural model, you should first convert the type of your data to acceptable input type of your neural framework.
For example, if you are using pytorch, the type of your input tuple is (int, int). You need to convert it into (torch.LongTensor, torch.LongTensor) such that it can be accepted by your neural model.
You will also need to manually batch your data. For simplicity, you can just build a big matrix with dimension (number_of_examples, 2) and then select data batch by batch.
There is a function call (batch_index_gen) that might be helpful.
Write your code in the cell below. Print out the type of your input data.
def batch_index_gen(batch_size, size):
batch_indexer = []
start = 0
while start < size:
end = start + batch_size
if end > size:
end = size
batch_indexer.append((start, end))
start = end
return batch_indexer
batch_index_gen(8, 50)
(2). Training your model. (5 pt)¶
You could now train your model batch by batch using whatever optimizer you want.
In order to keep track of your training, you should also print out the loss every 1000*X batch.
(For a vocabulary with 1,000 words, it will take ~35mins for one epoch depending on your computer.)
Write your code in the cell below. Print out the loss every 1000*X batch and your final average loss.
(2) Visualization¶
In this step, you need to visualize your word vectors by dimension reduction. (e.g. PCA or t-SNE)
You can write your code using matplotlib and scikit-learn. Or you can also upload your word vectors and vocabulary to http://projector.tensorflow.org.
Write your code or attach your visualization images in the cell below and show the data points for ["man", "men", "woman", "women"] and ["i", "he", "she", "my", "his", "her"].
If you are not satisfied with the quality of your word vector from visualization (in most cases), you could try to change some parameters in your model (e.g. vocabulary_size, embedding_dimension) and re-train your word embedding.
Tips:
You can use the code below to generate the vector file and word file needed in http://projector.tensorflow.org.
np.savetxt("vectors.tsv", <"Your_word_embedding_in_numpy_format">, delimiter='\t') with open("words.tsv", encoding="utf-8", mode="w") as words_f: for word in itos: words_f.write(word + "\n")
You might found those regular expressions helpful when searching words in http://projector.tensorflow.org.
^man$|^woman$|^men$|^women$
^i$|^he$|^she$|^my$|^his$|^her$
- For attaching image into notebook file, move your image file into the same directory and write html code below in markdown mode (same mode for this cell).
<img src="<your_screenshop_file>" alt="" style="width: 500px;"/>
Examples:
7. Vector evaluation (5 pt)¶
Upload your vector file to http://www.wordvectors.org and evaluate your vector. You should make sure your file has the correct format. Report your result by attaching a screenshot of your result in the cell below.
Again, if you are not satisfied with the quality of your word vectors from the evaluation (in most cases), you could try to change some parameters in your model (e.g. vocabulary_size, embedding_dimension, different optimizer, different total_number_epoch, batch_size) and re-train your word embedding.
Example:
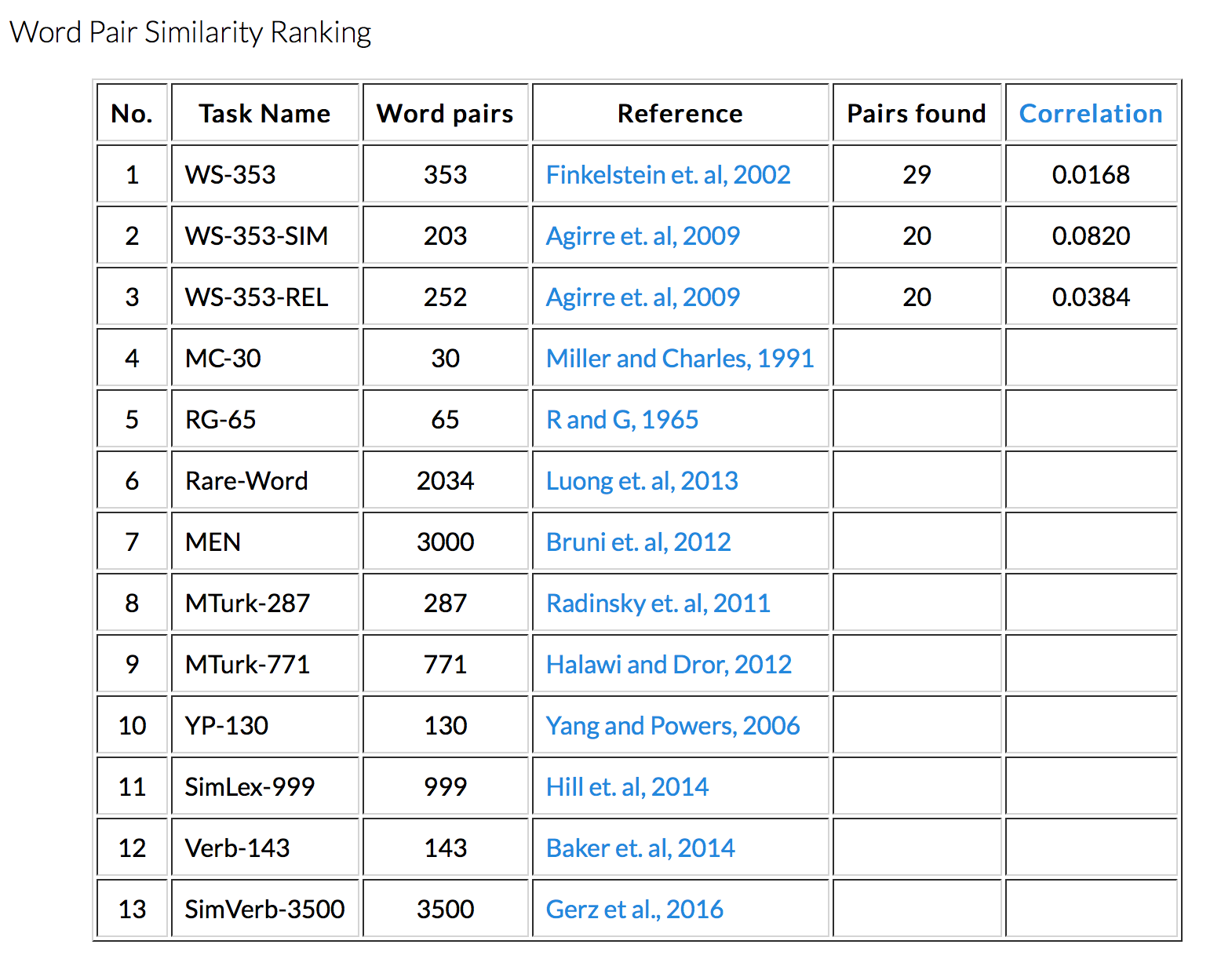
8. Extra materials¶
(1). Reading (3 pt)¶
You have trained your own toy word embedding but there are two important tricks the homework didn't cover.
Read http://mccormickml.com/2017/01/11/word2vec-tutorial-part-2-negative-sampling/ and write a summary about:
- Subsampling Frequent Words
- Negative Sampling
Explain why we need these two tricks?
(2). Subsampling and negative sampling (Optional with 10 pt bonus)¶
This is an optional problem.
Reimplement your model using subsampling and negative sampling and then re-train your embedding with at least 5,000 words in your vocabulary. (K=>5,000)
9. Additional analysis (5 pt)¶
This course is designed to train you as an NLP researcher. A researcher should not only be able to implement newly emerged models and algorithms and get them to work but also give reasons and intuitions behind every decision you make during your research (e.g. parameter and structure design).
In this section, write down anything you think that is important in this homework.
It could be:
- The problems you encountered during the implementation and how you resolve it.
- You were not satisfied with the quality of your word vector from visualization and you made some changes to (or it fails to) improve it. Why do you think those changes can (might) be helpful?
Use your imagination and try to record every detail of your experiments. The bonus will be given to novel and reasonable thoughts.